1. 아키텍처 설계
수정 전 무지성 기획
사실 가장 처음 생각했던 방법은 DB를 활용한 방법이었습니다. 그나마 효율적인 방법을 고려해보고자 RDS의 구매내역 데이터를 생성할 때 복합키(시계열 & 아이템ID)로 DynamoDB에 Count하는 방식이었습니다. 굳이 db를 나눈 이유는 조회한 데이터를 쿼리만 하는 DB를 분리하여 I/O연산과 쿼리연산을 최소할 수 있지 않을까 생각했기 때문입니다. 그렇게 전체적인 흐름은 아래 그림과 같게 구현되었습니다. 이에 따라 정상적인 요청이 들어왔을 때 5분마다 다른 랭킹 화면을 볼 수 있게 됩니다.
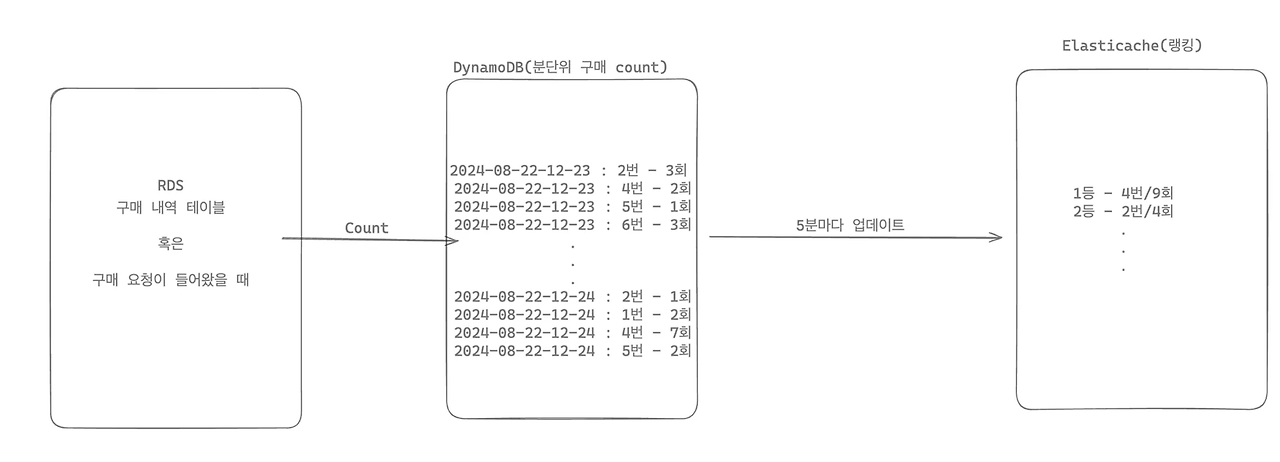
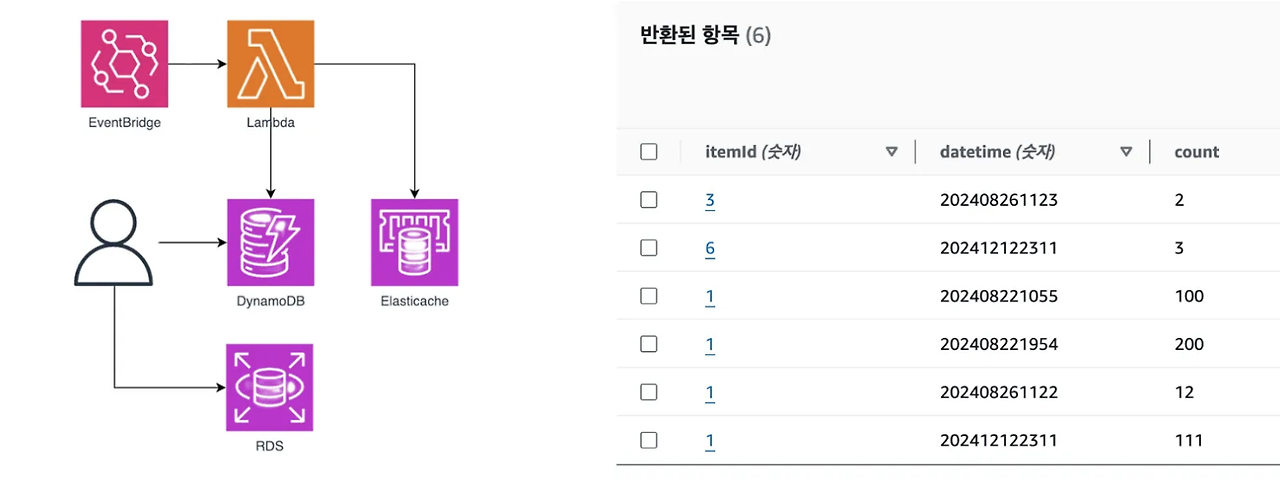
하지만 그럼에도 대규모 트래픽을 고려하면, DB 부하와 DynamoDB 비용 등등 5분마다 업데이트 되는 데이터는 로그 활용됨이 맞다고 생각했습니다.
이에 따라 CloudFront에서 생성된 로그에 따른 데이터 처리를 고려했습니다. 간단하게 설명하자면 트래픽이 CloudFront를 통해 들어오면 Amozon Kinesis, Firehose, S3, Glue, Athena 등을 통해 분석한 결과를 5분마다 Elasticache에 업데이트 함으로써 효율적인 실시간의 실시간 시스템을 구축하기로 계획했습니다.
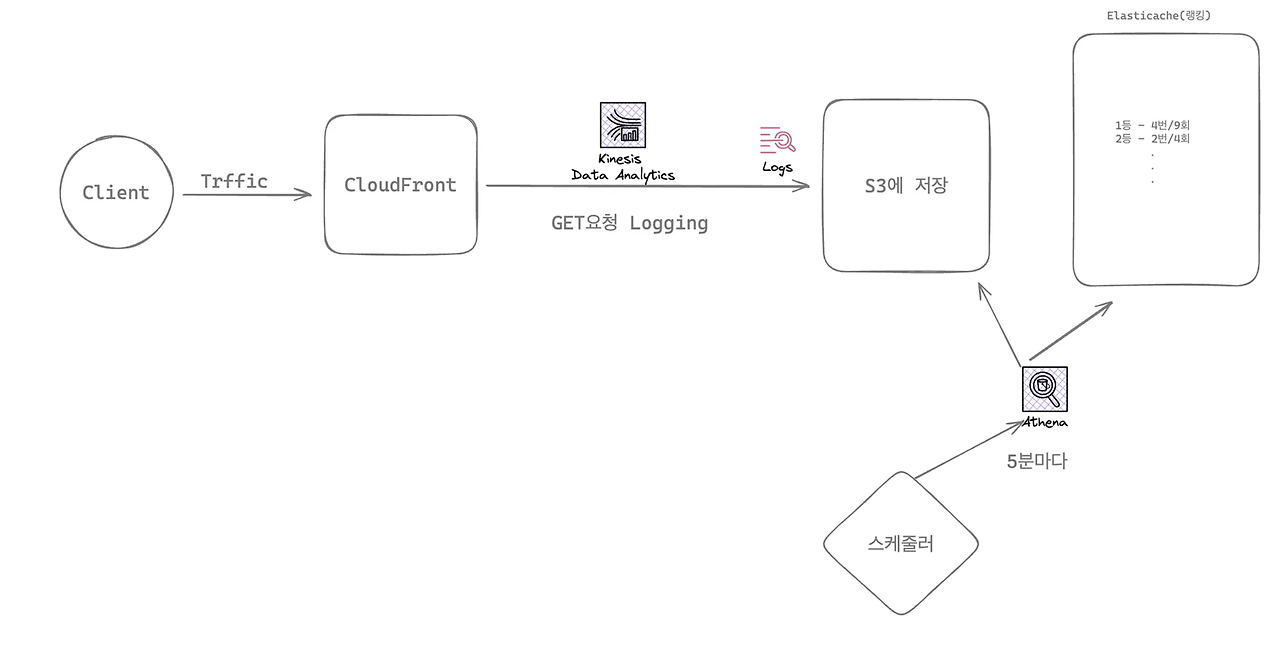
2. AWS Kinesis Data Streams 구현
우리는 CloudFront의 로그를 활용하기로 했습니다. 그럼 먼저 로그를 남기는 방식에 대해서 정해야 합니다. CloudFront의 로깅 방식에는 표준 로그, 실시간 로그가 있습니다.(엣지 함수, AWS CloudTrail 도 있기는 함) 어떤 기술이든 첫 경험은 basic을 선택하는 저이기에 평소의 저였다면 표준 로깅 방식을 활용했을 것입니다. 하지만 기술에 대한 설명을 읽어보던 중 다음 대목을 발견했습니다.
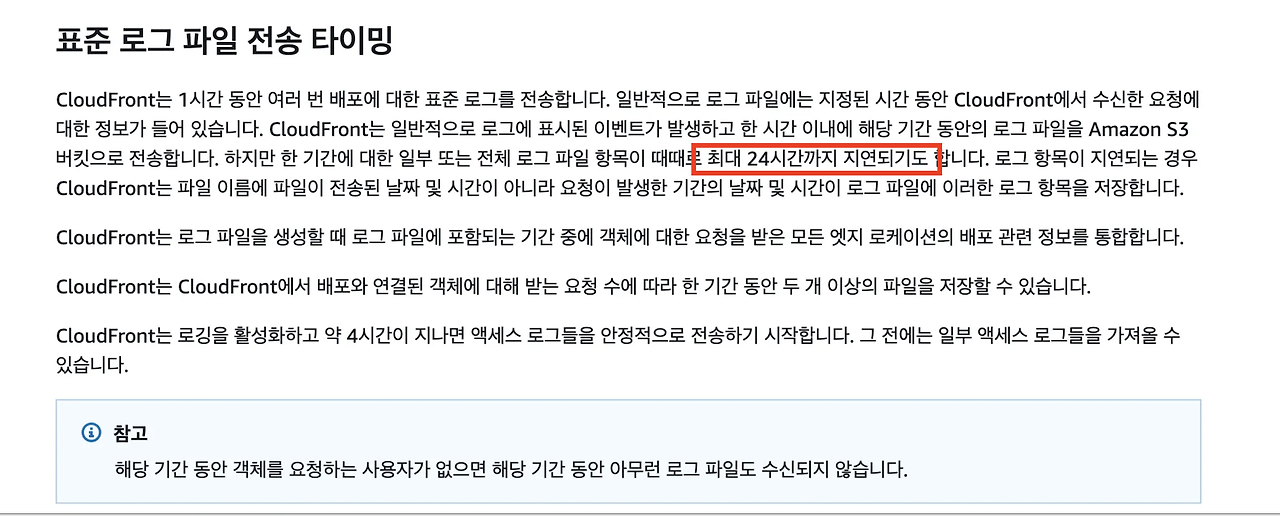
이처럼 Cloudfront의 표준 로그 방식에는 큰 단점이 있었습니다. 바로 24시간까지 지연되기도 한다는 점이었는데요. 이는 저희가 세운 실시간의 실시간이라는 타이틀을 전혀 사용할 수 없는 방법이었습니다.
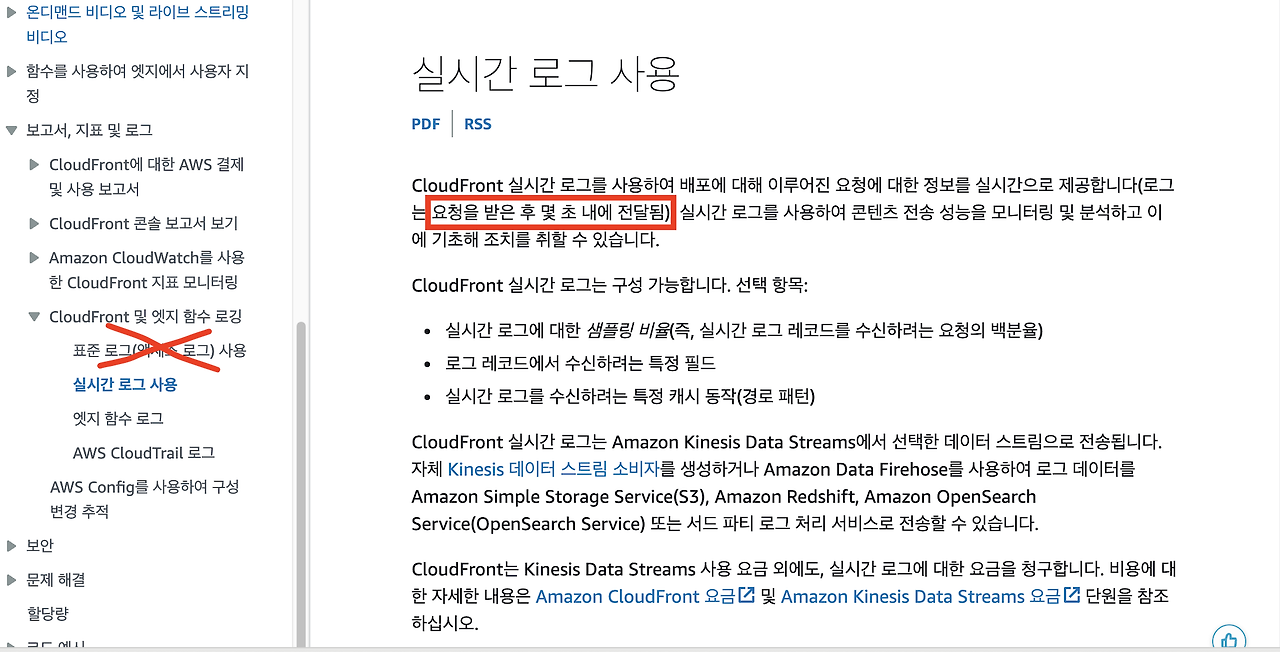
이에 따라 이름부터 매력적인 실시간 로그를 사용하고자 계획했습니다. 이제 사설은 그만하고 실습을 진행해보겠습니다.
1. CloudFront 실시간 로그 구성 설정
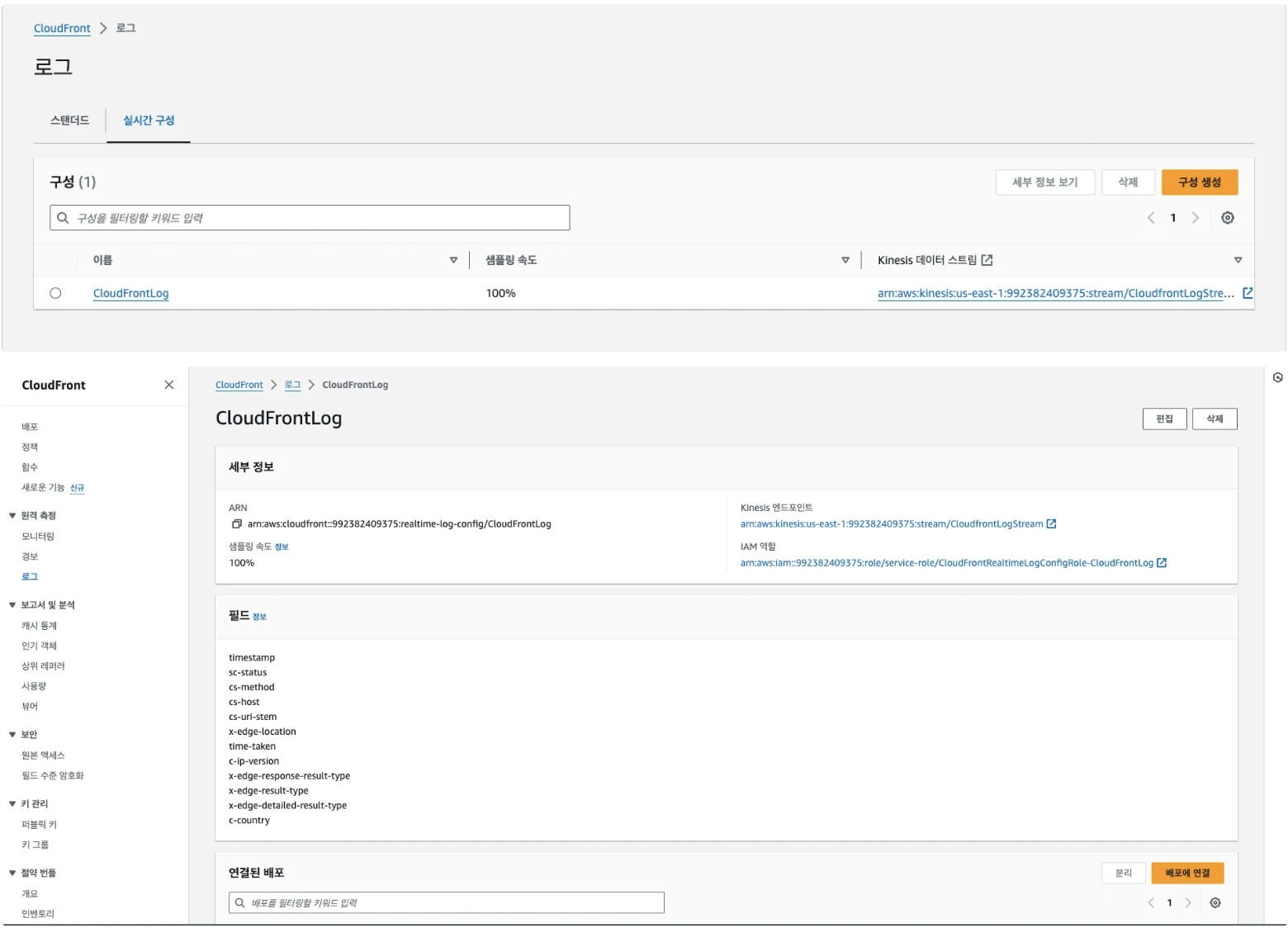
- CloudFront에서 수집할 필드를 먼저 설정해줍니다. 사실 CloudFront의 로그 이전에 2번인 Kinesis 먼저 구성을 완료한 상태에서 로그를 연결해주어야 합니다. CloudFront에서 생성된 로그가 Kinesis에 의해서 스트리밍되기 때문입니다.
- 필드는 33가지를 설정할 수 있지만 필수적인 필드와 이후 다른 비즈니스 로직을 고려한 필드(리전별 코드) 몇 개 추가해줍니다.
- 참고로 샘플링 속도는 Kinesis Data Stream으로 전송되는 최종 사용자 요청 비율입니다. 모든 요청을 받고 싶으니 100%로 하겠습니다.
2. Kinesis 생성 및 구성
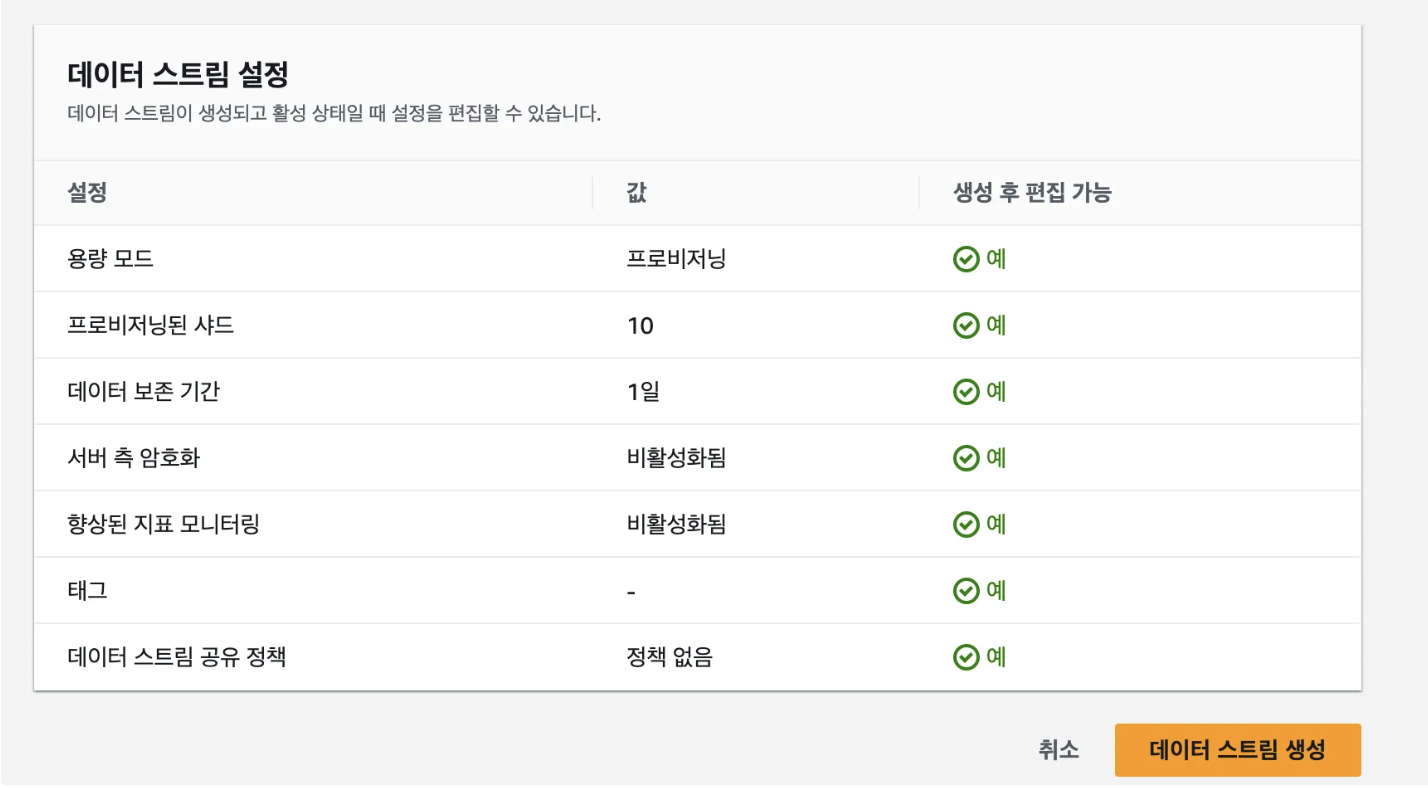
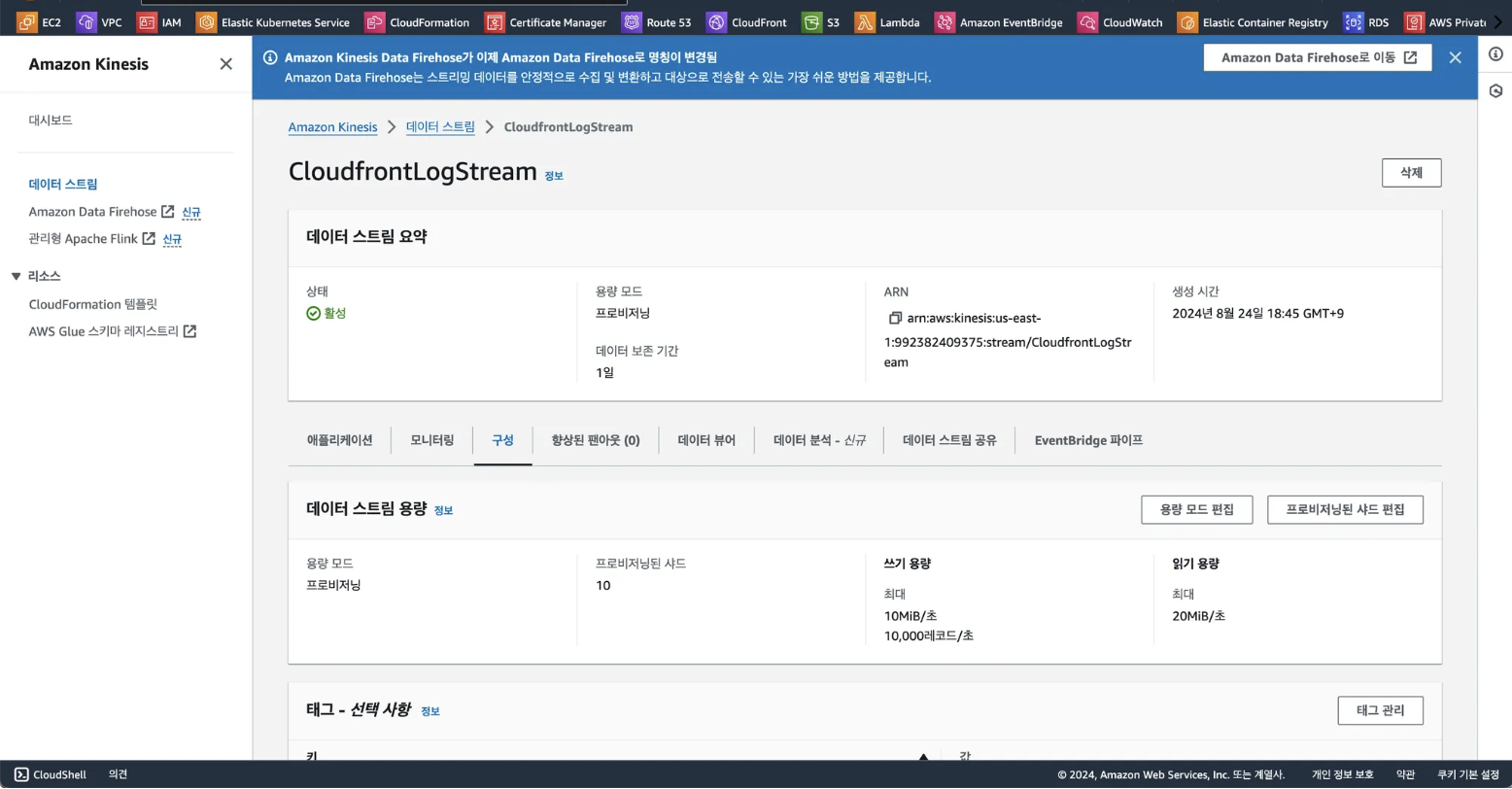
- Kinesis를 생성함으로써 CloudFront에서 들어온 요청에 대한 로그를 실시간으로 스트리밍합니다.
- 해당 과정에서 샤드의 개수를 선택할 수 있는데 샤드 1개는 초당 1000MB를 처리할 수 있는 리소스이며 10개로 설정한 이유는 실제 로그의 데이터가 어느정도 일 지 알 수 없었기 때문입니다.
- 이후 확인한 결과 53만건의 요청이 수집되었을 때 1GB 가량이었기 때문에 사실상 샤드는 10개까지 필요하지 않다고 볼 수 있었습니다.
3. Firehose 생성 및 구성
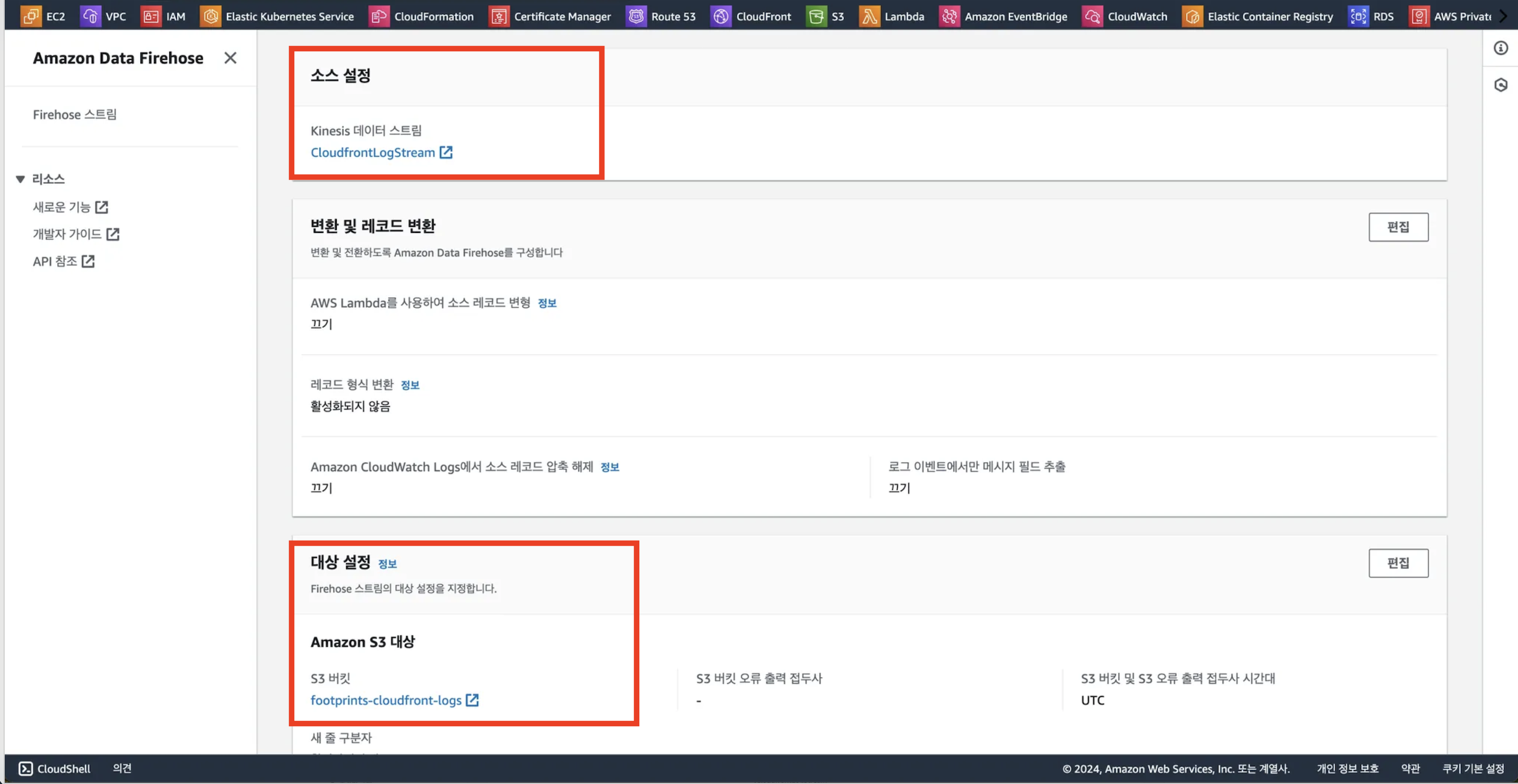
- Firehose는 스트리밍 데이터를 다양한 목적지로 로드하는 소비자 서비스입니다.
- 즉, Kinesis 스트림에 올라온 수집된 로그 데이터를 Amazon S3 로 업로드하는 역할을 합니다.

이런 과정을 거쳐 수집된 로그가 실시간으로 S3 버킷에 쌓이게 됩니다. 그럼 이제부터는 해당 로그들을 정제하여 보기 좋게 처리해야 합니다.
4. Athena 쿼리 작성 및 Glue 활용 테이블 정의
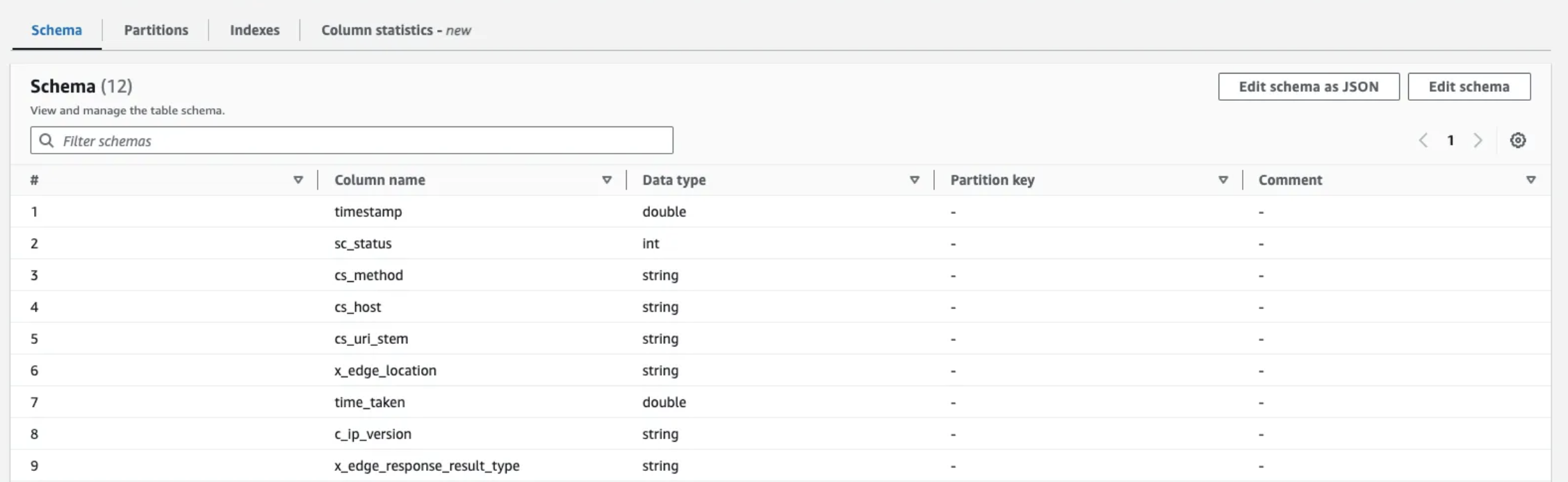
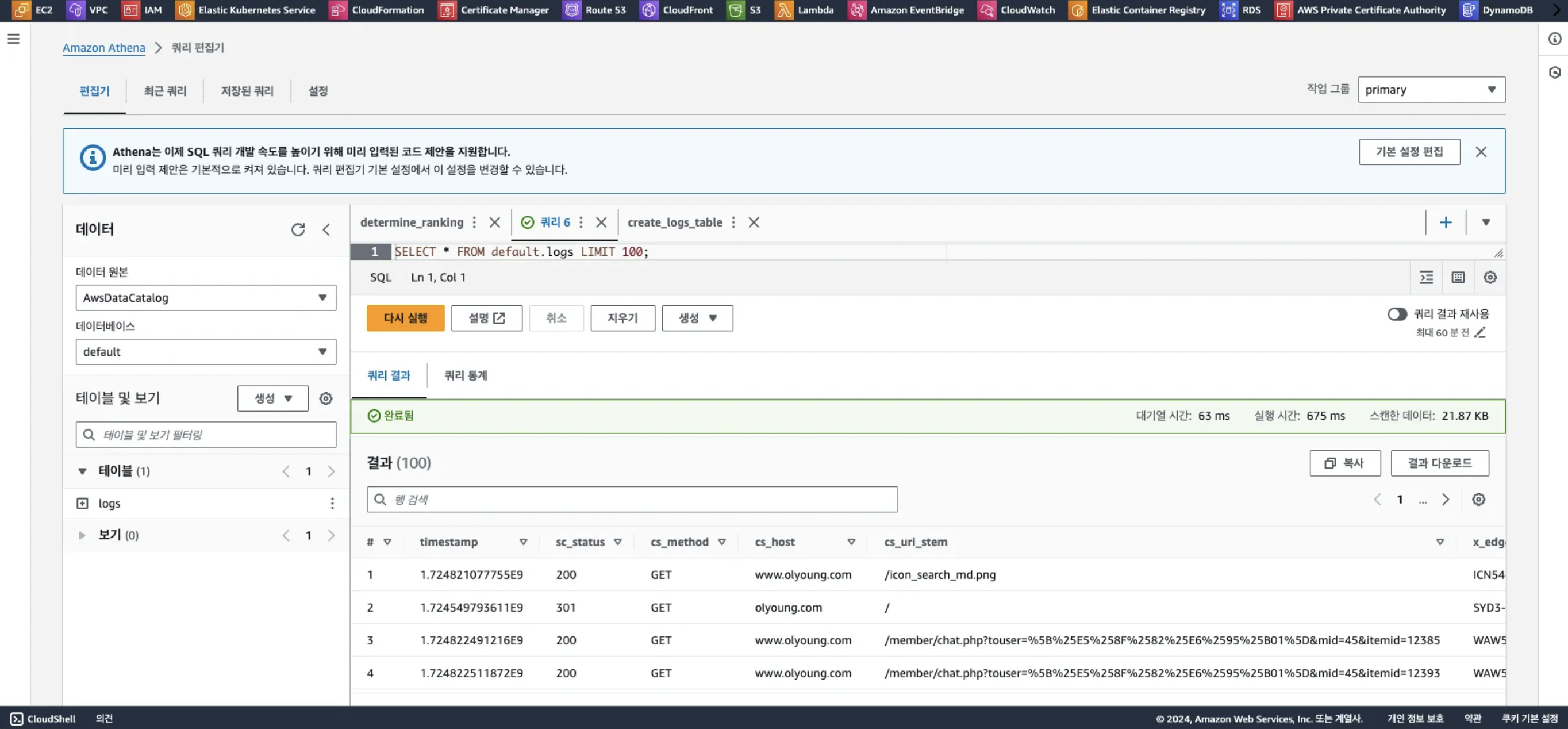
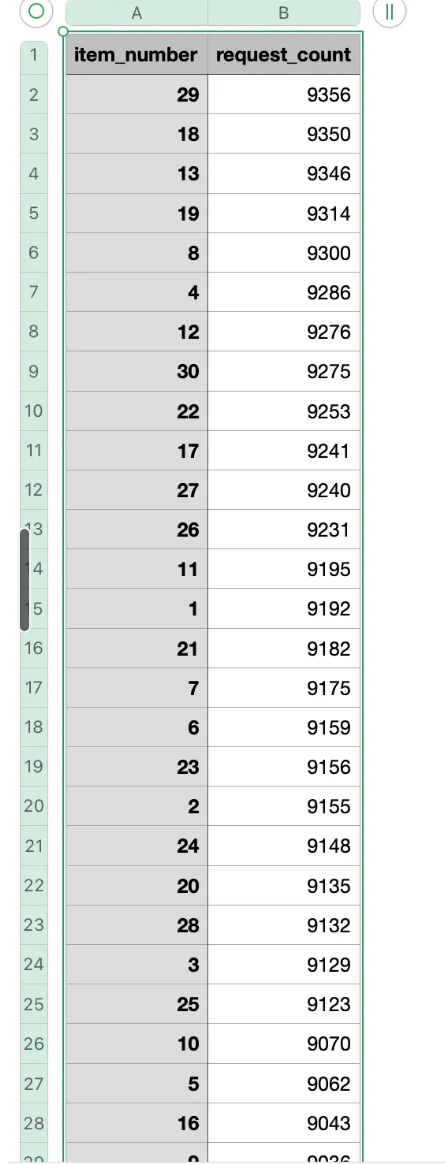
우리가 정의한 방식으로 요청이 잘 들어왔는 지 상위 100개의 데이터를 표준 SQL을 통해 조회한 화면입니다. 이제 스케줄링을 통해 실제 데이터가 ElastiCache로 업데이트 될 수 있게 람다함수를 작성합니다.
5. 람다함수 작성
import boto3
import time
from datetime import datetime
def lambda_handler(event, context):
athena_client = boto3.client('athena')
# 현재 시간 가져오기
now = datetime.utcnow()
year = now.strftime('%Y')
month = now.strftime('%m')
day = now.strftime('%d')
hour = now.strftime('%H')
print(now)
# Athena 쿼리 정의
query = f"""
WITH extracted_logs AS (
SELECT
REGEXP_EXTRACT(cs_uri_stem, '/api/items/([0-9]+)', 1) AS item_number,
from_unixtime(timestamp) AS log_datetime
FROM logs
WHERE cs_uri_stem LIKE '/api/items/%'
AND from_unixtime(timestamp) BETWEEN (current_timestamp - interval '1' hour) AND current_timestamp
)
SELECT
item_number,
COUNT(*) AS request_count
FROM extracted_logs
WHERE date_format(log_datetime, '%Y') = '{year}'
AND date_format(log_datetime, '%m') = '{month}'
AND date_format(log_datetime, '%d') = '{day}'
AND date_format(log_datetime, '%H') = '{hour}'
AND date_format(log_datetime, '%i') = date_format(current_timestamp, '%i')
GROUP BY item_number
ORDER BY request_count DESC;
"""
# Athena 쿼리 실행
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': 'default' # 데이터베이스 이름
},
ResultConfiguration={
'OutputLocation': 's3://get-ranknig/',
}
)
query_execution_id = response['QueryExecutionId']
print(f'QueryExecutionId: {query_execution_id}')
# 쿼리 상태 확인
status = 'RUNNING'
while status in ['RUNNING', 'QUEUED']:
time.sleep(3) # 10초 대기
result = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
status = result['QueryExecution']['Status']['State']
print(f'Query status: {status}')
if status == 'SUCCEEDED':
print('Query succeeded')
else:
print(f'Query failed: {result["QueryExecution"]["Status"]["StateChangeReason"]}')
return {
'statusCode': 200,
'body': f'Query execution status: {status}'
}(해당 코드는 사실 완성된 버전이 아닙니다.. 미처 최종 버전을 백업하지 못한 채 계정이 삭제되었기에..ㅜㅜ)
어쨌든 이렇게 집계된 랭킹은 바로 EastiCache에 올리지 않고 분석된 로그를 남기기 위해 S3에 한번 업로드합니다.
이를 트리거로 하여 실제 ElastiCache 에 랭킹을 업데이트 하는 람다를 작성합니다.
3. 최종 결과
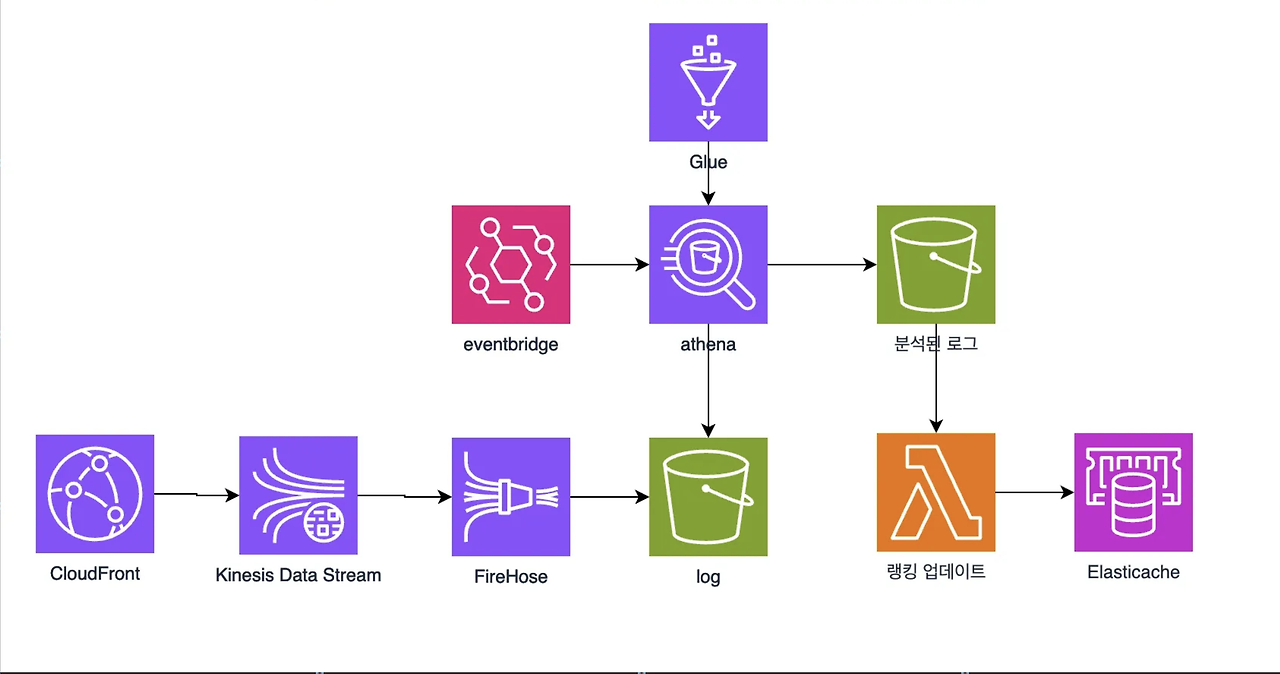
결과적으로 최종 아키텍처가 완성되었습니다!
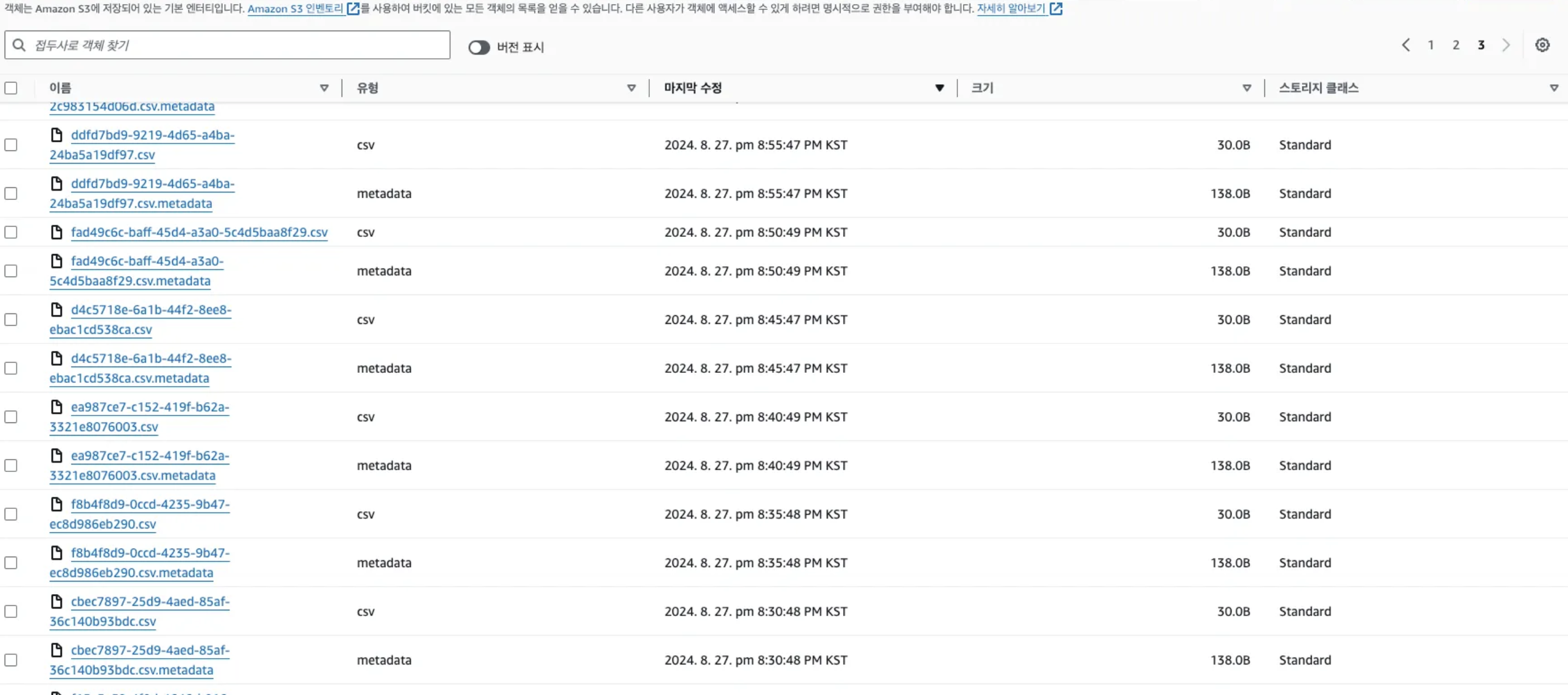
이처럼 분석된 결과가 5분에 하나씩 생성된 것을 볼 수 있습니다. 요청이 없을 때는 Redis에 저장된 데이터는 전부 빈 값으로 업데이트 되었던 이슈가 있어 이 부분은 Application 단에서 Default값을 주어 처리하였습니다.

다소 과한 샤드 10개를 사용했음에도 불구하고 DynamoDB와 비교하여 절반에 가까운 비용절감을 얻어냈고, 샤드를 적정개수인 1개로 설정하면 30분의 1 로 비용이 절약됩니다. Elasticache 비용은 이전 아키텍처와 동일하게 계산에 넣지 않았기 때문에 굳이 넣지 않았습니다.
4. 개선점
데이터 형식을 Parquet 형식으로 변환하여 분석에 최적화된 구조로 저장할 수 있다고 합니다. 적절한 테스트와 면밀한 요청 분석을 통해 샤드의 개수를 적절하게 선택할 수 있어야 하는 것이 개선해야 할 점입니다.